Dereje T. Abzaw 👋
Innovative Full Stack Developer 🖥️ & AI Engineer with 8+ Years in Software & AI

Innovative Full Stack Developer 🖥️ & AI Engineer with 8+ Years in Software & AI
Client For:
Services:
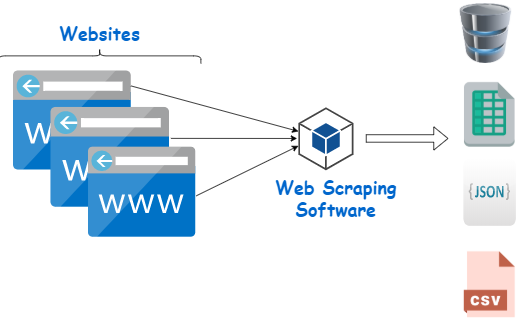
For this project, I developed a web scraping solution using BeautifulSoup to extract district-level data. The goal was to automate data extraction, providing accurate and up-to-date information to enhance data-driven decision-making.
Research: I began by studying the target web pages to understand their structure and identify the key data points Exxon needed. This involved analyzing the HTML layout and determining the best approach to extract consistent and meaningful district-level insights.
Information Architecture: The data was spread across multiple web pages with varying HTML structures and dynamic content, which made extraction more complex. The challenge was to map the website's structure effectively and ensure consistent data retrieval across all districts.
Extracting data reliably was complicated by inconsistent HTML structures and dynamic content across the web pages. Standard scraping methods couldn't handle these variations, which risked incomplete or inaccurate data extraction—jeopardizing the reliability of the insights needed.
The automated scraping tool I built extracted district-level data with high accuracy and efficiency, reducing manual data collection efforts by 80%. This solution provided timely and reliable insights, enabling more informed and agile decision-making across their districts.